2.6 Infer the labels for a new sentence
In the previous sections, we learned the structure of BiLSTM-CRF model and the details of CRF loss function. You can implement your own BiLSTM-CRF model by various opensource frameworks (Keras, Chainer, TensorFlow etc.). One of the greatest things is the backpropagation of on your model is automatically computed on these frameworks, therefore you do not need to implement the backpropagation by yourself to train your model (i.e. compute the gradients and to update parameters). Moreover, some frameworks have already implemented the CRF layer, so combining a CRF layer with your own model would be very easy by only adding about one line code.
In this section, we will explore how to infer the labels for a sentence during the test when our model is ready.
Step 1: Emission and transition scores from the BiLSTM-CRF model
Let us say, we have a sentence with 3 words: $\mathbf{x} = [w_0, w_1, w_2]$
Moreover, we have already got the emission scores from the BiLSTM model and the transition scores from the CRF Layer below:
| $\mathbf{l_1}$ | $\mathbf{l_2}$ | |
|---|---|---|
| $\mathbf{w_0}$ | $x_{01}$ | $x_{02}$ |
| $\mathbf{w_1}$ | $x_{11}$ | $x_{12}$ |
| $\mathbf{w_2}$ | $x_{21}$ | $x_{22}$ |
$x_{ij}$ denotes the score of $w_i$ being labelled $l_j$.
| $\mathbf{l_1}$ | $\mathbf{l_2}$ | |
|---|---|---|
| $\mathbf{l_1}$ | $t_{11}$ | $t_{12}$ |
| $\mathbf{l_2}$ | $t_{21}$ | $t_{22}$ |
$t_{ij}$ is the score of label transition from label $i$ to label $j$.
Step 2: Start Inference
If you are familar with Viterbi algorithm, this section would be easy for you. But if you are not, please do not worry about that. Similar with the previous section, I will explain the algorithm step-by-step. We will run the inference algorithm from left to right of the sentence as shown below:
- $w_0$
- $w_0$ → $w_1$
- $w_0$ → $w_1$ → $w_2$
You will see two variables: obs and previous. previous stores the final results of previous steps. obs denotes the information from current word.
$\mathbf{alpha_0}$ is the history of best scores and $\mathbf{alpha_1}$ is the history of the corresponding indexes. The details of these two variables will be explained when they occur. Please see the picture below: You can treat these two variables as “marks” the dog made along the road when he explores the forest and these “marks” would be helpful to assist him finding the way to get back home.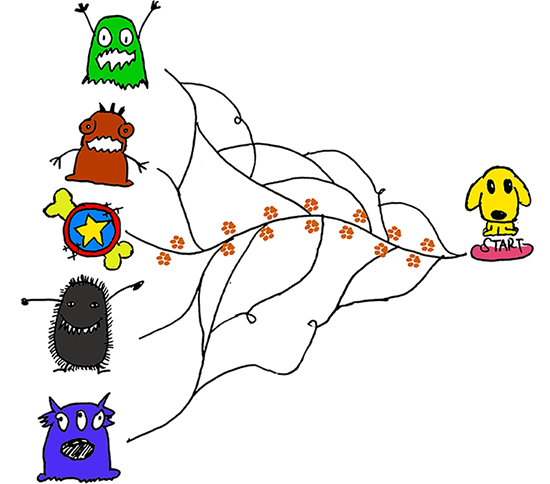
$w_0$:
$obs = [x_{01}, x_{02}]$
$previous = None$
Currently, we are observing the first word $w_0$. So far the best label for $w_0$ is straightforward.
For example, if $obs = [x_{01}=0.2, x_{02}=0.8]$, obviously, the best label for $w_0$ should be $l_2$
Because there is only one word and no transitions between labels, the transition scores are not used.
$w_0$ → $w_1$:
$obs = [x_{11}, x_{12}]$
$previous = [x_{01}, x_{02}]$
(Be careful and follow closely)
1) Expand the previous to:
2) Expand the obs to:
3) Sum previous, obs and transition scores:
Then:
You may be wondering there is no difference with the previous section when we compute the total score of all the paths. Please be patient and careful, you will see the differences very soon.
Change the value of previous for the next iteration:
For example, if our scores is:
Our previous for the next iteration would be:
What is the meaning of previous? The previous list stores the maximum score to each label of the current word.
[Example Start]
For example:
We know that in our corpus, we totally have 2 labels, $label1(l_1)$ and $label2(l_2)$. The index of these two labels are 0 and 1 respectively (Because in programming, the index starts from 0 not 1).
$previous[0]$ is the maximum score of the path which ends with the $0^{th}$ label, $l_1$. Similarly, $previous[1]$ is the maximum score of the path which ends with $l_2$. In each iteration, the variable $previous$ stores the maximum score of the path which ends up with each label. In other words, in each iteration, we only keep the information of best path to each label(). The information of paths which have less scores will be discarded.
[Example End]
Back to our main task:
At the same time, we also have two variables to store the history information(scores and indexes), $alpha_0$ and $alpha_1$.
For this iteration, we will add the best scores into $alpha_0$. For your convenience, the maximum score of each label was underlined.
In addition, the corresponding column indexes were kept in $alpha_1$:
For explanation, the index of $l_1$ is 0 and $l_2$ is 1. So $(1,1)=(l_2,l_2)$ that means, for the current word $w_i$ and label $l^{(i)}$:
$(1,1)$
$=(l_2,l_2)$
$=$(we can get the maximum score 0.5 when the path is $\underline{l^{(i-1)}=l_2}$ → $\underline{l^{(i)}=l_1}$) ,
we can get the maximum score 0.4 when the path is $\underline{l^{(i-1)}=l_2}$ → $\underline{l^{(i)}=l_2}$)
$l^{(i-1)}$ is the label of the previous word $w_{i-1}$.
$w_0$ → $w_1$ → $w_2$:
$obs = [x_{21}, x_{22}]$
$previous = [0.5, 0.4]$
1) Expand the previous to:
2) Expand the obs to:
3) Sum previous, obs and transition scores:
Then:
Change the value of previous for the next iteration:
Let’s say, the scores we get in this iteration is:
Therefore, we can get the latest previous:
Actually, the larger one between $previous[0]$ and $previous[1]$ is the score of the best predicted path.
At the same time, the maximum scores of each label and indexes will be added into $alpha_0$ and $alpha_1$:
Step 3: Find out the best path which has the highest score
This is the last step! You are most done! In this step, $alpha_0$ and $alpha_1$ will be used to find the path with highest score. We will check the elements in these two lists from the last one to the first one.
$w_1$ → $w_2$:
Firstly, check the last element of $alpha_0$ and $alpha_1$: $(0.8,0.9)$ and $(1,0)$. 0.9 means when the label is $l_2$, we can get the highest path score 0.9. We also know the index of $l_2$ is 1, therefore check the value of $(1,0)[1]=0$. The index “0” means the previous label is $l_1$(the index of $l_1$ is 0). So we can get the best path of $w_1$ → $w_2$: is $l_1$ → $l_2$.
$w_0$ → $w_1$:
Second, we continue moving backwards and get the element of $alpha_1$: $(1,1)$. From the last paragraph we know that the label of $w_1$ is $l_1$(index is 0), therefore we can check $(1,1)[0]=1$. So we can get the best path of this part ($w_0$ → $w_1$:): $l_2$ → $l_1$.
Congratulations! The best path we get is $l_2$ → $l_1$ → $l_2$ for our example.
Next
The following sections will focus on the implementation and the code will be released soon.
(Sorry for my late update, I will try my best to squeeze time for updating the following sections.)
References
[1] Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K. and Dyer, C., 2016. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360.
https://arxiv.org/abs/1603.01360
Note
Please note that: The Wechat Public Account is available now! If you found this article is useful and would like to found more information about this series, please subscribe to the public account by your Wechat! (2020-04-03)
When you reprint or distribute this article, please include the original link address.